SAS统计应用¶
描述统计¶
常用统计量¶
-
定性变量
proc freq
- 频数frequence
- 比例percent
- 众数mode
-
定量变量
proc means, univariate
- 集中信息
- 均值mean
- 中位数median
- 波动信息
- 极差range
- 四分位差qrange
- 方差var
- 标准差std
- 变异系数cv
- 形状信息
- 偏度系数skewness
- 峰度系数kurtosis
- qqplot
- 集中信息
means过程¶
proc means data=dataname
mean median mode # 中心水平———集中信息
n nmiss # 非缺失值个数、缺失值个数
std var range qrange cv # 离散水平——波动信息,cv变异系数
kurtosis skewness; # 形状信息——峰度,偏度,简写为kurt,skew
maxdec=2; # 保留小数
by var1;
class var2;
var weight length1-length3;
output out=dataname;
run;
univariate过程¶
proc univariate data=dataname;
var 分析变量;
class 分类变量;
histogram 分析变量;
inset 统计量; # 在直方图中插入统计量
qqplot 分析变量; # 画qq图
qqplot var1/normal(mu=est sigma=est); # 估计正态
run;
统计推断¶
点/区间估计+假设检验
对于一个样本:
- 背后的分布对应的参数是什么?——点估计
- 背后的分布对应的参数范围是什么?——区间估计
- 背后的分布某个参数是否等于(小于、大于)某个值?——假设检验
- 数据是否来自正态分布?——假设检验
区间估计¶
proc means
对置信水平的理解
不断重复抽取样本,用此方法产生的许多区间中95%会覆盖真的参数。
而不是参数落入区间的概率是95%,当区间确定了,参数是否落入区间是一个确定事件没有概率可言。
# 标准误、置信区间、置信水平
proc means data=dataname maxdec=2 stderr clm alpha=.1;
var var1;
# 不加var默认全部变量
run;
假设检验¶
思想和反证法类似:
- 做出原假设H0 -->导出矛盾(p值很小,原假设是小概率事件)--> 假设不成立,拒绝原假设。
假设零假设成立,可以得到该统计量的分布,再看这个统计量的实现值(realization)属不属于小概率事件。如果是小概率事件(p值小于显著性水平)那么就拒绝原假设,该检验显著;否则说没有足够的证据拒绝原假设,该检验不显著。
在零假设下,检验统计量取其实现值(沿着备择假设的方向)更加极端的概率称为p-值。
假设检验的两类错误:
- 第一类错误——拒真
- 第二类错误——取伪
通常原假设是受到保护的,没有充足的证据不能推翻的。
正态样本均值推断¶
h0是原假设,做单边检验:均值不高于225(upper上界)。
proc ttest data=dataname h0=225 sides=u alpha=0.05;
var score;
run;
sides参数:
- u(upper)
- l(lower)
- 2(双边检验)
检验统计量T: $$ T = \frac{\bar{X}-\mu_0}{s/\sqrt{n}}\sim t(n-1) $$
两独立正态样本均值差的推断¶
class语句
proc ttest data=dataname;
class gender;
var score;
run;
T检验,注意方差同性,如果不满足同方差但是mn很大的时候看satterwaite检验.
两个配对正态样本均值差的推断¶
paired语句
proc ttest data=dataname;
var x;(x=x1-x2)
run;
or
proc ttest data=dataname;
paired x1*x2;
run;
正态性检验¶
univariate过程,normal选项
proc univariate data=dataname normal;
var x;
run;
- N<2000,以W检验为准
- N>2000,不输出W检验,以D检验为准
proc univariate data=dataname normal;
var x;
class var2;
run;
卡方检验——拟合优度检验¶
$$ \chi^2=\sum_{i=1}^m\frac{(n_i-np_{i0})^2}{np_{i0}} $$
proc freq data=bear;
tables brand/nocum chisq;
weight num;
run;
卡方检验——独立性检验¶
$$ \chi^2=\sum^I_{i=1}\frac{(n_{ij} - n\times\hat{p_{ij}})}{n\times\hat{p}_{ij}} $$
proc freq data=smoke;
tables lungorn*smoke/ nocum chisq;
weight num;
run;
符号检验——非参数检验¶
X与Y两者分布是否相同,样本做差,符号检验.
proc univariate data=pig normal;
var diff;
run;
秩和检验——非参数检验¶
npar1way过程
检验多个类的分布是否相同:
proc npar1way <options>;
var ...;
class ...;
run;
options可以选median(中位数评分)或wilcoxon(秩和)计算各个分类来检验。
相关系数¶
proc corr data=dataname
spearman kendall pearson
plot = matrix(histogram)
outk=d1
outp=d2
outs=d3;
# 分不同相关系数类型输出数据集
run;
proc corr data=dataname plots=matrix; # plot选项可以画出矩阵散点图
var var1 var2 var3;
with var4;
# var4*(var1~3)
run;
spearman相关系数$\rho$
源数据$X_i,Y_i$被转换为等级数据$x_i,y_i$ $$ \rho = \frac{\sum _i (x_i-\bar{x})(y_i-\bar{y})}{\sqrt {\sum _i (x_i-\bar{x})^2\sum _i(y_i-\bar{y})^2}} $$
kendall相关系数$\tau$ $$ \tau = \frac{(\text{num of concordant pairs})-(\text{num of discoreant pairs})}{n(n-1)/2} $$
Pearson相关系数$r$(样本相关系数用r表示) $$ r = \frac{\sum _i (X_i-\bar{X})(Y_i-\bar{Y})}{\sqrt {\sum _i (X_i-\bar{X})^2\sum _i(Y_i-\bar{Y})^2}} $$
回归分析¶
回归分析框架¶
建模¶
通过一些已知的变量信息来预测一些未知的变量信息,定量地理解变量之间的变化关系。
最简单的模型——线性模型¶
-
模型写法: $$ Y_i = \beta_0+\beta_1x_i+\epsilon_i \ \epsilon_i \sim _{i.i.d.}N(0,\sigma^2) $$
- $\sigma^2$影响着噪声的大小
- 随机误差的均值假设为0
-
估计方法
- 找一条直线:$\hat{y_i}=\hat{\beta_0}+\hat{\beta_1}x$,使得总的误差最小
- 这里的误差我们使用误差平方和 $$ min_{\hat{\beta_0},\hat{\beta_1}} \ \sum_{i=1}^n(y_i-\hat{\beta_0}-\hat{\beta_1}x_i)^2 $$
最小二乘估计:¶

模型评价¶
考虑增加了自变量Xi带来的收益
- $\text{SST}=\sum_{i=1}^n(y_i-\bar{y})^2$
- 没有xi时拟合的误差总和
- $\text{SSE}=\sum_{i=1}^n(y_i-\hat{y})^2$
- 有xi时拟合的误差总和
- $\text{SSR}=\text{SST-SSE}=\sum_{i=1}^n(\hat{y}-\bar{y})^2$
- 有xi时减少的误差总和
决定系数:
$$ 0\leq R^2 = {SSR\over SST} \leq1 $$
衡量Y的取值多大程度上可以被X的取值解释。R方越大,模型解释能力越强。
模型的参数推断¶
一个样本得到的$\hat{\beta_i}$只是真正系数的一个观测,需要对系数进行假设检验:

国家统计局居然还有这种小知识库
模型的使用¶
注意解释变量系数时的说法:
- 截距项:当所有自变量为0时,若此模型仍然成立,Y的期望的估计值为截距项
- x系数:当给定其他所有自变量值保持不变时,x每增加一单位,Y期望增加值为系数
理论:多元线性回归¶
增加无关变量R方也会上升,因此我们需要 调整R方:
调整R方:
$$ R^2_a = 1-(1-R^2)(\frac{n-1}{n-p-1}) $$
- p为自变量个数
- n为样本容量
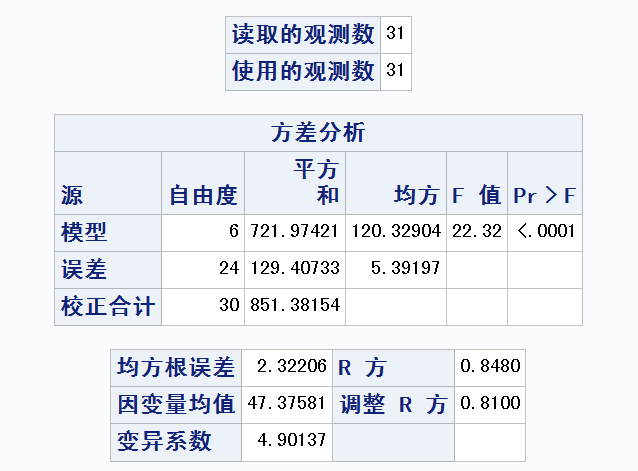
整个模型的显著性检验——F检验¶
方差分析表:
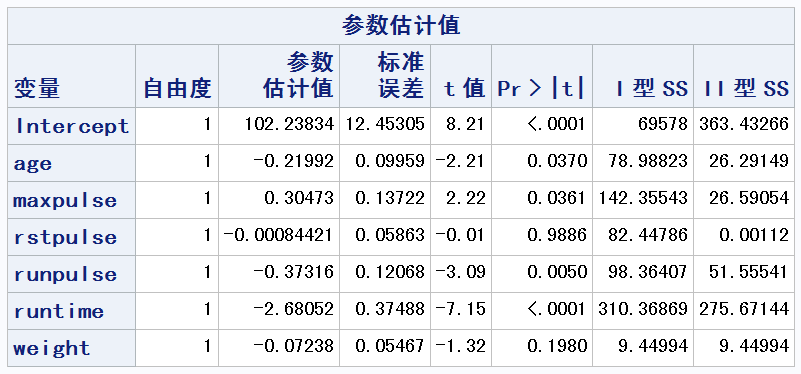
每个自变量系数的显著性检验——t检验¶
共线性问题¶
变量不显著或是变量系数和预期不一致(符号不对),说明可能出现了多重共线性问题。
如果多个自变量之间相关系数较大,可以考虑删去和响应变量相关性最弱的自变量。
共线性的量化指标:
- 方差膨胀因子VIF $$ \text{VIF}_i=\frac{1}{1-R_i^2} $$
其中$R_i^2$是$X_i\sim其他自变量回归的R^2$
经验法则:
- VIF大于4需要进一步检查
- VIF大于10出现严重共线性,$X_i$可以被其他变量替代
变量选择¶
- 向后消元法backward
- 先所有变量加入模型,然后提出不显著的模型,重复直到所有变量显著性检验通过
- 向前选择法forward
- 逐步回归法stepwise
模型诊断¶
也就是验证下面的一系列假设:
- 每个自变量对于Y取值的影响均是线性关系
- 残差与自变量无关
- 散点图
- 残差之间相互独立(最难检验)
- 时间序列图,检测趋势
- 残差之间同方差性
- 残差-拟合值的散点图,观察趋势
- 残差正态性
- 残差的QQ图
- 异常值检验
- 杠杆率图 RstudentByLeverage
- 影子价格?偏导数?
- Rstudent是studentized residuals学生化残差,标准化之后的残差
- 检查离群值
- CooksD
- 如果一个观测被排除在外,由此造成的回归系数变化进而Y的拟合值有多大
- 杠杆率图 RstudentByLeverage
AIC、SC准则¶
- $\text{AIC}=-2log(L)+2p$
- $\text{SC}=-2log(L)+log(n)p$也称为BIC
其中L为似然函数在最大似然估计处的取值,越大越好;也就是AIC、SC越小越好。这些准则用于比较对于同一个数据,哪个模型更好。并非绝对指标,不可以用于比较不同数据的模型。
实战:线性回归¶
拟合模型¶
reg过程需要quit
reg过程在运行的时候需要run然后手动quit:
proc reg data=dataname plots(only label) = (RstudentByLeverage RstudentByLeverage);
model sales= population snow /clb p vif alpha=.1;
# clb置信区间,confidence limits for beta
# p产生残差分析
# vif方差膨胀因子——检查共线性
# alpha
id zone;
run;
quit; # 别忘记了
预测¶
proc append base=data1 data=data2;
run;
proc reg data=dataname;#默认只使用非缺失值建模
model sales= population/ p;
run;
quit;
or
proc reg data=dataname outest=regout;#输出模型得到的参数
model sales= population/ p;
run;
proc score data=sales score=RegOut out=mypred type=parms;#使用参数预测
var price;
run;
变量选择¶
proc reg data=dataname;
model sales= population snow/
selection = backward slstary=0.05;
run;
quit;
还可以使用forward或者stepwise:
forward中slentary=value,默认为0.5stepwise两个参数都可以指定,slentary,slstary,默认均为0.15
理论:广义线性模型¶
设响应变量$Y$,均值为$\mu_Y$,某个链接函数$g$,广义线性模型为:
$$ g(\mu_Y)=\beta_0+\beta_1x_1+...+\beta_kx_k $$
- $Y\sim \text{Bernoulli}(p),\quad g=\text{logit}$
- 即为logistic回归
- $Y\sim \text{Bernoulli}(p),\quad g=\Phi^{-1}$
- 即为probit回归
- $Y\sim \text{Normal}(\mu,\sigma^2),\quad g=\text{idnetity}$
- 即为线性回归,适合响应变量是连续的
- $Y\sim \text{Poisson}(\lambda),\quad g=\log$
- 即为poisson回归,适合响应变量是计数数据
logit和probit模型的异同
Logit和Probit模型都是用于处理二元因变量(如“是/否”、“成功/失败”)的回归模型,但它们在函数形式、假设和应用场景上存在一些异同。以下是它们的详细对比:
相同点:
- 用途
- 都用于建模二元分类问题(因变量为0或1)。
- 例如:预测用户是否购买产品、贷款是否违约等。
- 输出概率
- 两者都通过链接函数将线性预测值($X\beta$)映射到[0,1]区间,输出事件发生的概率。
- 估计方法
- 通常使用最大似然估计(MLE)进行参数估计。
- 非线性关系
- 均假设自变量与因变量之间存在非线性关系(通过S型曲线拟合)。
不同点:
| 特征 | Logit模型 | Probit模型 |
|---|---|---|
| 链接函数 | Logistic函数(累积逻辑分布) | 标准正态分布的逆CDF($\Phi^{-1}$) |
| 函数形式 | $P(Y=1) = \frac{e^{X\beta}}{1+e^{X\beta}}$ | $ P(Y=1) = \Phi(X\beta)$ |
| 分布假设 | 逻辑分布(厚尾) | 标准正态分布(薄尾) |
| 系数解释 | 优势比(Odds Ratio) | 边际效应(需计算) |
| 极端概率 | 对极端值更敏感(尾部更厚) | 对极端值更保守 |
| 计算便利性 | 解析解更简单(常用于机器学习) | 需数值积分(计算略复杂) |
| 应用领域 | 更常见于医学、社会科学 | 更常见于经济学、金融 |
如何选择?
- 理论基础
- 如果数据生成过程符合正态分布(如经济学中的潜变量假设),选择Probit。
- 如果关注优势比或需要更直观的解释(如医学研究),选择Logit。
- 计算效率
- Logit的解析解更简单,适合大数据或实时预测场景。
- Probit需数值积分,计算成本略高。
-
结果差异
- 实际应用中,两者的预测结果通常非常接近(系数需按比例缩放后比较)。
- Logit的系数约为Probit的1.6~1.8倍(因方差差异)。
-
边际效应:Probit的边际效应需通过$\phi(X\beta)\beta$计算($\phi$为标准正态PDF),而Logit的边际效应为$ \frac{e^{X\beta}}{(1+e^{X\beta})^2}\beta $。
- 扩展模型:两者均可扩展为有序(Ordered)或多元(Multinomial)模型。
总结:
- Logit:直观、易解释、计算高效,适合大多数分类问题。
- Probit:更符合正态假设,适合经济学或需要严格分布假设的场景。
在实践中,若无明确理论偏好,Logit通常因其便利性被优先采用。
实战:logistic回归¶
回归的结果为发生比(或者说是log-odds),x每增加一个单位,event的发生比乘以$exp(\beta)$
proc logistic data=bankrupt;
model Z = x1 - x3/selection=forward;
run; # 默认水平Z取第一个,为0
proc logistic data=bankrupt;
model Z(enevt='1') = x1 - x3; # 可以指定event
run;
这里的model语句还可以这么写:
model enevts/trials = <effects></options>;
理解为,事件发生的频率:
proc logistic data=shuttle;
model damaged / n = tmp;
run;
实战:probit回归¶
probit回归也使用logistic过程,只不过可以指定link函数
proc logistic data=dataname;
model Z=x1-x2/ link=normit;
run;
这里加了link选项,指定了链接函数(默认是logit函数 $$ \text{logit}(p) = \log\frac{p}{1-p} $$
$$ \text{probit}(p) = \Phi^{-1}(p) $$ 其中$\Phi(x)$是$N(0,1)$的累积分布函数: $$ \Phi(x)=\int_{-\infty}^x \exp(-\frac{x^2}{2})dx $$
genmod过程¶
genmod过程更加通用,啥都能做。是真正的广义线性模型(Generalized Linear Models)过程
线性回归:
proc genmod data=dataname;
model Y=x1+x2/ dist=NORMAL link=identy;
run;
logistic回归:
proc genmod data=dataname;
model Y=x1+x2/ dist=BIN link=logit;
run;
聚类分析¶
聚类分析就是通过某种距离度量把样本按照距离远近划分为若干类的过程。
常用距离¶
明可夫斯基距离¶
$$ d_{ij}=\{\sum_{k=1}^p|x_{ik}-x_{jk}|^q\}^{1/q} $$
q=2时,即为欧氏距离,它的缺点是受到量纲影响大,标准化可以解决~
match¶
$$ d_{12}=\frac{m_2}{m_1+m_2} $$
m1是配合的变量数,m2是不配合的变量数
cosine余弦距离¶
$$ c_{ij}=\frac{X\cdot Y}{|XY|} $$
求距离矩阵¶
使用distance过程可以很方便地计算距离矩阵:
proc distanse data=数据集 out=数据集 method=方法;
freq 变量;
id 变量;
var 变量类型;
run;
距离度量:
- euclid
- cov
- corr
- l(p)——明可夫斯基距离p
- match
- dmatch
- dsqmatch
- cosine
变量类型:interval, ratio, ordinal等
proc distanse data=family out = dis1 method=Euclid;
var ordinal(age--num/std=Std);
run;
标准化:std默认标准化方法。
系统聚类法¶
cluster聚类¶
输入原始数据的情况下,默认使用欧氏距离进行聚类分析:
proc cluster data=dataname
outtree = dataname
method = ave|war|sin|com|cen
std
pseudo #输出伪t方统计量
;
var x1-x6;
id province;
run;
method:类间距离的定义
- single最短距离算法
- 类与类之间的距离定义为最近观测之间的距离
- complete最长距离算法
- 类与类之间的距离定义为最远观测之间的距离
- centroid重心法
- 重心(均值)之间的欧氏距离
- average类平均法
- 所有观测对之间的平均距离
- ward离差平方和法
- 类中各个观测到中心的平方欧氏距离之和称为类内离差平方和
类间距离: $$ D_{KL}^2 = W_M-(W_K+W_L) $$ $W_K,W_L$是类内离差平方和,$W_M$是K和L合并之后的类内平方和。如果两类之间距离小,合并之后的增加的离差平方和应该较小。
画出谱系图¶
proc tree data=dataname horizontal; #默认是竖直的,可选水平
run;
proc tree data=dataname noprint ncl=5 out=dataname; #分为5类,输出为数据集
id province;
run;
采用非欧氏距离¶
需要先计算距离矩阵:
proc distance data=dataname method=dcorr out=distdcorr;
var interval(div_1986--div_1990);
id company;
run;
然后把距离矩阵输入cluster过程:
proc cluster data=distdcorr method=ward pseudo;
id company;
run;
什么是距离矩阵¶
在SAS中距离矩阵是一种data type,我们甚至可以认为定义一个距离矩阵:
data dist(type=distance);# 指定数据集类型
input A B C D$;
cards;
1 2 3 A
4 5 6 B
7 8 9 C
;
run;
快速聚类法¶
Kmeans聚类:

proc fastclus data=数据集
maxc=3 #指定类的个数,默认为100
replace=random #随机指定初始凝聚点,否则选前k个
out=clusters
cluster=cl #输出数据集中类别的变量名
maxiter=100 #最大迭代次数
least=2 #明式距离中的q,明可夫斯基距离
;
var 变量名;
run;
标准化数据¶
proc stdize data=dataname out = std_data;
var x1-x6;
run;
如何确定类的个数¶
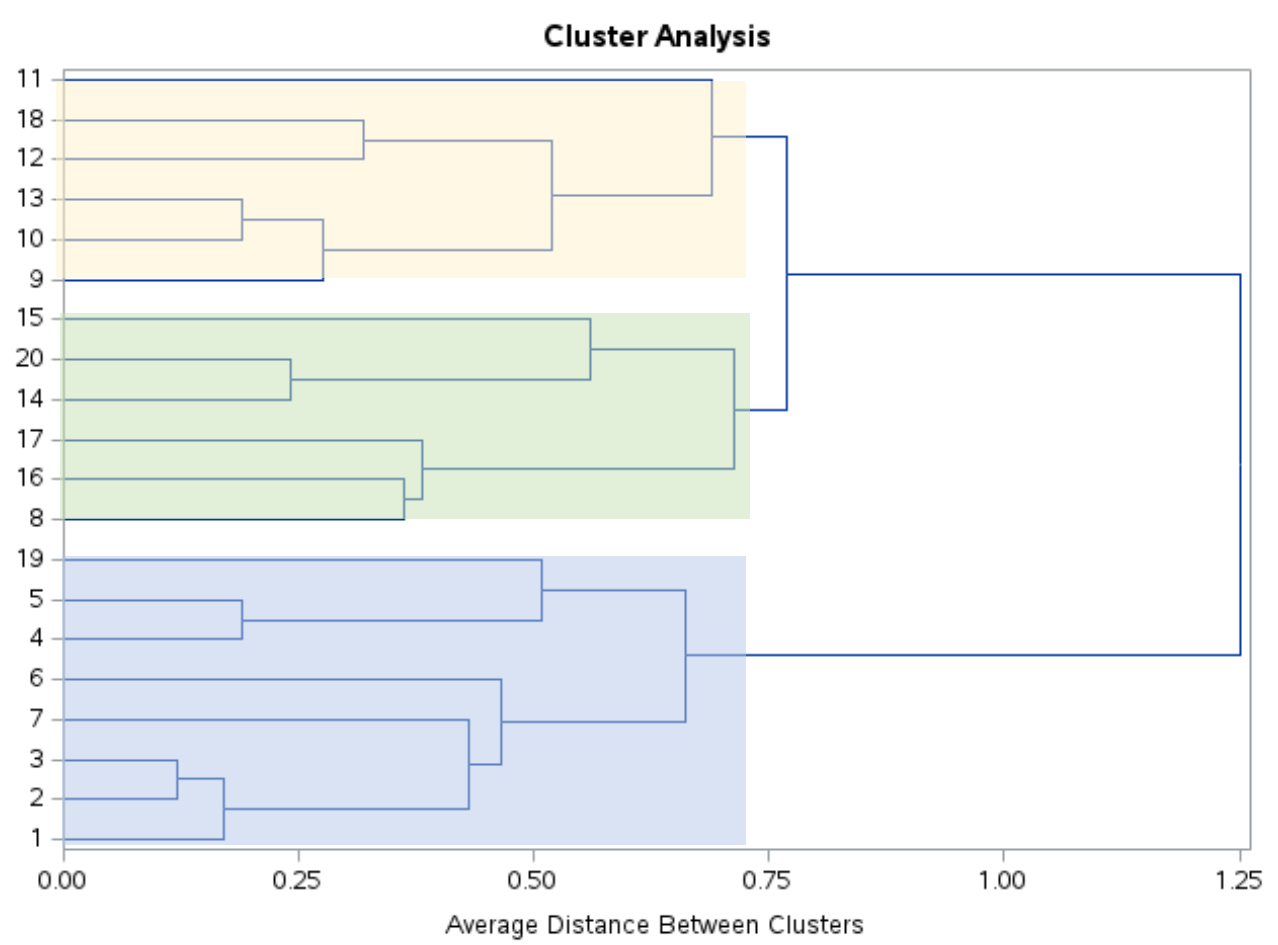
谱系图¶
从谱系图来看,寻找一个合适的树高,做截断即可:
散点图¶
也可以通过散点图来观察聚类效果。
但是很多时候变量较多的时候没法看,这时候可以使用主成分分析法降低数据纬度再看。
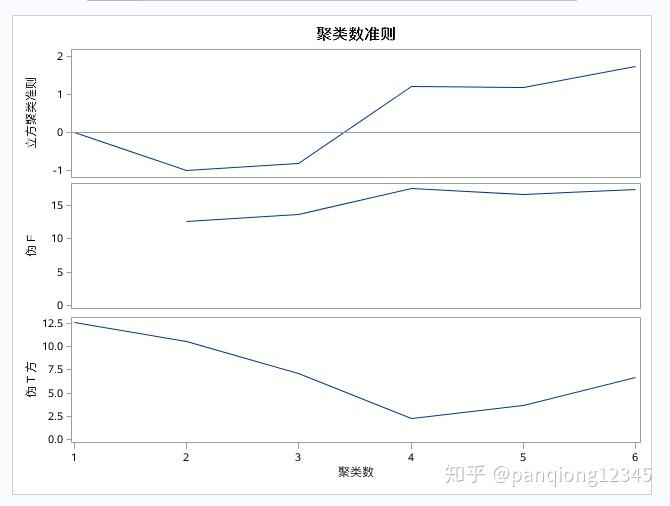
使用统计量伪T方¶
SAS会直接帮我们计算:
创建日期: 2022-07-26 03:55:55
广告
人要恰饭的嘛🤑🤑